| ПОЗНАВАТЕЛЬНОЕ Сила воли ведет к действию, а позитивные действия формируют позитивное отношение Как определить диапазон голоса - ваш вокал Игровые автоматы с быстрым выводом Как самому избавиться от обидчивости Противоречивые взгляды на качества, присущие мужчинам Вкуснейший "Салат из свеклы с чесноком" Натюрморт и его изобразительные возможности Применение, как принимать мумие? Мумие для волос, лица, при переломах, при кровотечении и т.д. Как научиться брать на себя ответственность Зачем нужны границы в отношениях с детьми? Световозвращающие элементы на детской одежде Как победить свой возраст? Восемь уникальных способов, которые помогут достичь долголетия Классификация ожирения по ИМТ (ВОЗ) Глава 3. Завет мужчины с женщиной
Оси и плоскости тела человека - Тело человека состоит из определенных топографических частей и участков, в которых расположены органы, мышцы, сосуды, нервы и т.д.
| Нейронные сети в системах автоматического распознавания речи
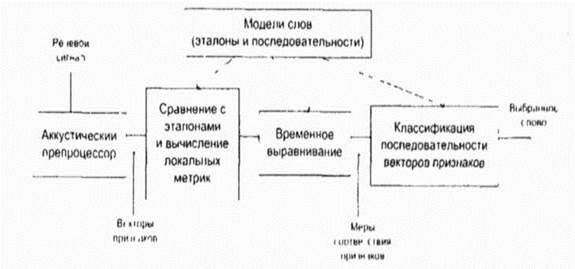
Хорошо известно, что речь человека характеризуется высокой степенью изменчивости. Это обусловлено несколькими причинами [6]. Во-первых, даже для одного и того же говорящего, реализации одних и тех же акустических единиц будут отличаться по своему спектральному составу и длительности произношения. Это может быть связано с изменениями эмоционального состояния человека, условий, в которых он находится. Во-вторых, наличие коартикуляционных эффектов приводит к тому, что произношение слов и фонем сильно зависит от их контекста. В-третьих, к изменениям в речевом сигнале приводят помехи различного характера. Принимая во внимание все эти факторы, и учитывая ряд других ограничений, следует отмстить, что для высококачественного распознавания речи в реальном времени требуются вычислительные средства с высоким быстродействием. Одним из способов снижения этого требования является распараллеливание вычислений, которое естественным образом достигается при использовании искусственных НС, реализованных на нейрокомпьютерах. К настоящему времени разработаны высокоэффективные нейронно сетевые модели для распознавания коротких речевых сегментов и наборов схожих по звучанию изолированных слов. Часть из этих моделей успешно 62 объединены с традиционными подходами для создания распознавателей больших словарей, изолированных слов и слитной речи [6]. Рассмотрим простейшую схему распознавания изолированных слов, представленную на рис. .1 [6].
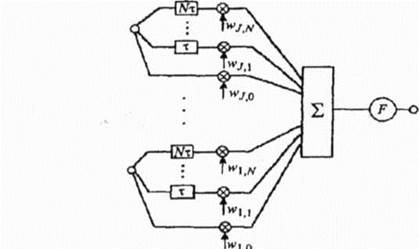
Рис. 3 1 Схема распознавателя изолированных слов Процесс распознавания в этом случае можно разделить на три этапа. На первом этапе акустический препроцессор преобразует входной речевой сигнал в последовательность векторов признаков или акустических векторов, извлекаемых через фиксированные промежутки времени. Как правило, эти векторы содержат спектральные или кепстральные коэффициенты, характеризующие короткие отрезки речевого сигнала. На втором этапе векторы сравниваются с эталонами, содержащимися в моделях слов, и вычисляются их локальные метрики или меры соответствия (в общем случае сравниваются речевые сегменты, представленные несколькими векторами признаков). На третьем этапе эти метрики используются для временного выравнивания последовательностей векторов признаков с последовательностями эталонов, образующими модели слов, и вычисляются меры соответствия для слов. Временное выравнивание используется для компенсации изменений в скорости произнесения. После выполнения всех этих операций распознаватель выбирает слово, для которого мера соответствия максимальна. При распознавании слитной речи локальные метрики полученные на втором этапе вычислений, используются для временного выравнивания и определения мер соответствия для отдельных предложений или высказываний. С целью высококачественного распознавания обычно используется дополнительный этап, позволяющий учесть семантические, синтаксические и прагматические ограничения. В схеме распознавания, изображенной на рис.3.1,НС наиболее успешно используются на второй стадии вычислений при расчете локальных метрик [87].Для статистических распознавателей с непрерывным наблюдением данные метрики являются монотонными функциями функций правдоподобия векторов признаков. Простейшие из этих функций, такие как логарифм функции правдоподобия для гауссовского распределения векторов независимых величин, могут быть рассчитаны с помощью однослойных сетей без их предварительного обучения (для известных параметров распределений) [6]. При вычислении более сложных метрик могут быть использованы многослойные перцептроны, способные вычислять функции любой сложности. При настройке весовых коэффициентов таких сетей используется способность многослойного перцептрона, имеющего достаточное число связей, аппроксимировать апостериорную вероятность классов после его обучения для выполнения классификации [6, ]. Данное свойство было успешно использовано для создания высокоэффективных гибридных подходов к распознаванию слитной речи, основанных на скрытых марковских моделях (СММ), где многослойные сети служат для вычисления правдоподобий состояний СММ . Использование НС в таких подходах позволяет учитывать при выполнении распознавания акустический контекст векторов наблюдений СММ и снять допущения относительно формы распределения этих векторов [6]. Распознаватели речи с дискретным наблюдением сначала выполняют векторное квантование и присваивают каждому вектору признаков определенный символ из кодовой книги. Затем на основе этих символов с помощью специальных таблиц, содержащих вероятности наблюдения символов для каждого эталонного вектора, вычисляются локальные метрики. Такие вычисления могут быть выполнены однослойными перцептронами, состоящими из линейных узлов, число которых равно числу эталонов. Число входов такого перцептрона должно быть равным числу возможных символов. Векторное квантование может быть выполнено с помощью сети, подобной карте признаков Кохонена. Такая сеть представляет собой двумерный массив узлов кодовой книги, содержащий по одному узлу на каждый возможный символ. Каждый узел вычисляет евклидово расстояние между входным вектором сети и соответствующим эталоном, представленным весами узла, после чего выбирается узел с наименьшим евклидовым расстоянием. Веса данной сети вычисляются с помощью алгоритма Кохонена, его модификаций [6] или с помощью любого другого традиционного алгоритма векторного квантования, использующего в качестве метрики евклидово расстояние (например, с помощью кластеризационно-го алгоритма к-средних [6,]. Многослойные нейронные сети также могут быть использованы для снижения размерности векторов признаков, извлекаемых препроцессором на начальном этапе распознавания. Такая НС имеет столько же выходов, сколько и входов, и один или более слоев скрытых узлов. При обучении НС ее веса подбираются так, чтобы она могла воспроизводить на выходе любой входной вектор через небольшой слой скрытых узлов. Выходы этих узлов после обучения сети могут быть использованы в качестве входных векторов меньшей размерности для дальнейшей обработки речи. В случае использоваться НС для классификации статических образов фонем, слогов и небольших словарей изолированных слов в качестве входного образа может быть выбран вектор признаков, характеризующий стационарный участок ее реализации. Эксперименты показывают, что в этом случае нейронносетевые классификаторы имеют примерно такую же точность распознавания, как и традиционные гауссовский классификатор и классификатор к ближайших соседей . Для учета динамической природы речи, то есть характера изменения параметров речевого сигнала во времени, в качестве статического входа НС может быть выбрано окно, включающее несколько последовательных во времени векторов признаков. Данное окно обычно размещается в начале или в конце распознаваемой фонемы, так как именно там наиболее проявляется динамический характер речи и имеется возможность учитывать ее контекст. Однако для высококачественного опознавания необходима точная сегментация обучающих и контрольных выборок для их временного выравнивания, которое на практике осуществить довольно сложно. описаны результаты экспериментов по исследованию перцеп-тронов и некоторых типов иерархических НС, используемых для распознавания статических образов изолированных слов и цифр. Показано, что в случае небольших словарей точность распознавания примерно равна точности распознавания коммерческих распознавателей и распознавателей, основанных на СММ. Особый интерес вызывают динамические нейросетевые классификаторы, разработанные специально для распознавания речи и включающие в свой состав короткие временные задержки и узлы, выполняющие временное интегрирование, или рекуррентные связи. Обычно такие классификаторы мало чувствительны к небольшим временным сдвигам обучающих и контрольных выборок и, следовательно, не требуют для высококачественной работы точной сегментации речевых данных. Использование динамических сетей при распознавании речи позволяет преодолеть основные недостатки, присущие статическим сетям, и, как показывают экспериментальные исследования, приводит к превосходному качеству распознавания для акустически схожих слов, согласных и гласных [6]. Частота ошибок у динамических сетей для задач с малым словарем часто оказывалась значительно ниже, чем у лучших альтернативных распознавателей, в том числе и основанных на СММ Нейронная сеть с временными задержками (НСВЗ) представляет собой многослойный перцептрон, узлы которого модифицированы введением временных задержек Узел, имеющий N задержек г, 2т, ,Nr , показан на рис 3 2 Он суммирует взятые в N+1 последовательных моментов времени J своих входов, умноженных на соответствующие весовые коэффициенты, вычитает порог и вычисляет нелинейную функцию F полученного результата Архитектура трехслойной НСВЗ, предложенной для распознавания трех фонем (или трех классов фонем), показана на рис 3 3 (на нем показаны связи только для одного выходного узла) На рис 3 3 показано, что обработка сетью входной последовательности акустических векторов эквивалентна прохождению окон временных задержек над образами узлов нижнего уровня На самом нижнем уровне эти образы состоят из сенсорного входа, т е акустических векторов Узлы скрытых слоев сети представляют собой движущиеся детекторы признаков и способны обнаруживать требуемые образы в любом месте входных последовательностей Благодаря тому что выходные узлы имеют равные веса связей со вторым слоем, любые моменты времени для таких детекторов являются равноправными Это делает сеть инвариантной к временным сдвигам обучающих и контрольных образцов фонем (для случая, когда эти сдвиги не столь велики, чтобы важные ключевые признаки оказывались за пределами входной последовательности сети) Простая структура делает НСВЗ подходящей для стандартизованной СБИС-реализации с загружаемыми извне весами
Рис 2 Архитектура НСВЗ Обзор нейросетевых структур, предназначенных для выполнения других функций при распознавании речи можно найти, например, в |