| ПОЗНАВАТЕЛЬНОЕ Сила воли ведет к действию, а позитивные действия формируют позитивное отношение Как определить диапазон голоса - ваш вокал Игровые автоматы с быстрым выводом Как самому избавиться от обидчивости Противоречивые взгляды на качества, присущие мужчинам Вкуснейший "Салат из свеклы с чесноком" Натюрморт и его изобразительные возможности Применение, как принимать мумие? Мумие для волос, лица, при переломах, при кровотечении и т.д. Как научиться брать на себя ответственность Зачем нужны границы в отношениях с детьми? Световозвращающие элементы на детской одежде Как победить свой возраст? Восемь уникальных способов, которые помогут достичь долголетия Классификация ожирения по ИМТ (ВОЗ) Глава 3. Завет мужчины с женщиной
Оси и плоскости тела человека - Тело человека состоит из определенных топографических частей и участков, в которых расположены органы, мышцы, сосуды, нервы и т.д.
| Многоуровневая организация памяти в вычислительной системе.
ЛЕКЦИЯ 3
Блок –схема памяти 2D
Запись Чтение В режиме записи и считывания в координатную обмотку подаются токи разного направления, причем ток осуществляющий считывание по величине в два раза больше и должен осуществлять перемагничивание сердечника (перевод его в нулевое состояние) В случае единичного состояния сердечника при считывании в обмотке считывания наводится ЭДС величина тока которой определяет считывание единицы. Если сердечник находился в состоянии нуля, то ток в обмотке считывания отсуствует так как отсуствует изменение магнитного потока, а ток помехи, возникающий от перемагничивания по частичному циклу усилителем чтения не воспринимается
БЛОК-СХЕМА 2DM
ФУНКЦИОНАЛЬНАЯ СХЕМА ПАМЯТИ DRAM
На данной схеме изображены два независимых этапа преобразования логического адреса в физический адрес: сегментация и страничное преобразование. Как видно из схемы механизм сегментации адресов в процессоре является самостоятельным и не связан с этапами преобразования логических адресов в физические и эта функция полностью возложена на этап страничного преобразования ,то есть механизм сегментации задействован всегда и в том случае, когда страничное преобразование не используется линейный адрес становится физическим автоматически. Следует отметить, что в некоторых архитектурах сегментация памяти используется как начальный или промежуточный этап преобразования логического адреса в физический. Примером тому архитектура процессоров фирмы IBM.
На выше приведенных рисунках приведены схемы распределения областей физической памяти по функциональному назначению( структура логической памяти) Дадим краткую характеристику некоторым областям . VGA и MDA области памяти (0A000-0BFFFF) Видео карты используют эти полученные в наследство области адресного пространства для маркировки своих буферов. По умолчанию доступ к этим областям передается на хаб- интерфейс, связывающий северный мост(MCH) c южным мостом (ICH), на котором расположены контроллеры всех интерфейсов ввода вывода. Однако ,если биты доступности к VGA установлены в конфигурационном регистре северного моста, то транзакции из этих областей пересылаются в графический адаптер AGP, подсоединенный к северному мосту то есть эти области передаются в распоряжение AGP. Но если в системе при конфигурации обнаружен монохромный адаптер, то область адресного пространства в памяти MDA передается безусловно этому адаптеру и все транзакции направленные в эту область переадресуютcя в MCH в южный мост. Область 0C000-FFFFF Эта область памяти разбивается на три части - расширенная область для ISAшины( 000C0000-000D0000) -расширенная область BIOS (000E 0000-000E FFFF) -область системного BIOS (000F0000-000FFFFF) по умолчанию после сброса эта область закрыта для чтения и записи и все обращения к ней транслируются на хаб – интерфейс к микросхеме BIOS. Однако MCH может копировать BIOS в свою память при установке соответствующего режима в контроллере памяти. Распределение областей памяти выше 1МГБ. ISA HOLE MEM. SPASE (окно в памяти для ISA) BIOS может открыть окно между 15мгб и 16мгб для переадресации транзакций на хаб- интерфейс, вместо того чтобы завершить на системной памяти. TSEGSMM (Сегмент области памяти для режима SMM) Эта область памяти находится под управлением программного обеспечения, осуществляющего режим SMM в системе ,этот регион памяти может быть размером от 128клб до1мгб. Доступ в эту область возможен, если она открыта или MCH получает специальный код транзакции на системной шине. В случае если область открыта, а агент на шине пытается обратится с несанкционированным для него обращением в эту область, транзакция аннулируется. Верхняя область памяти для режима SMM (FEDA0000-FEDBFFFF) Эта кэшируемая область адресного пространства дает возможность переадресации при обращении к ней в совместимую некэшируемую область между 000A 0000-000BFFFF. Область AGP/PCI Технология горячей замены выделяет дляAGP достаточное пространство для всех устройств , расположенных за мостом PCI-PCI,соединяющим AGP c системной шиной. Все обращения в эту область декодируются и передаются в AGP. Область памяти I/O APIC (FEC00000-FEC7FFFF) Эта область используется для связи контроллеров прерывания APIC , которые могут быть размещены на системной шине. Ввиду использования технологии горячей замены возникают трудности с идентификацией их на шине ,поэтому для них отводится область фиксированных адресов в памяти ,то есть используется технология адресации внешних устройств с отображением на адресное пространство памяти. Все обращения в область I/O APIC со стороны процессора пересылаются на хаб- интерфейс в южный мост.
Область для фиксации прерываний на системной шине (FEE00000-FEEFFFF) Эта область используется для передачи прерываний на системную шину. Любое устройство на AGP или на хаб- интерфейсе может формировать цикл обращения по записи в память по адресу 0FEEх хххх. MCH принимает эту запись совместно с данными на шине согласно протокола шины PCI и продвигая дальше на шину как сообщение о прерывании, блокируя цикл записи в память.
Реализация конвейера при считывании данных из памяти иллюстрируется на вышеприведенной схеме и временной диаграмме.
ОРГАНИЗАЦИЯ ПАМЯТИ SDRAM
t разрядов k p
t разрядов : : : :
e
ЛЕКЦИЯ 4,5 БЛОК-СХЕМА АССОЦИАТИВНОЙ КЭШ
КЭШ ПАМЯТЬ ПРЯМОГО ОТОБРАЖЕНИЯ
НАБОРНО-АССОЦИАТИВНАЯ КЭШ
Схема установки (сброса)
 CPBB CPBB

CPBD
CPBA
CPBD
Обращение B0 обращение B1 обращение B2 не было к AvB 0 B 0 D 0 C AvB 0 B 0 C 1 D AVB 0 A 1 D 0 C AVB 0 A 1 C 1 D CVD 1 B 0 D 0 A CVD 1 B 0 C 1 A CVD 1 A 1 D 0 B CVD 1 A 1 C 1 B
Результируящая таблица
1 1 х запись в B
1 0 x запись в A
0 x 0 запись в C
0 x 1 запись в D
ЛЕКЦИЯ 6
Блок-схема архитектуры Фон-Неймана.
БЛОК-СХЕМА ГАРВАДСКОЙ АРХИТЕКТУРЫ ЭВМ
БЛОК-СХЕМА СИГНАЛЬНОГО ПРОЦЕССОРА
СХЕМА АДРЕСАЦИИ ПРОЦЕССОРОВ INTEL
ЛЕКЦИЯ 9
БЛОКВЫБОРКИ КОМАНД( СХЕМА ПРОДВИЖЕНИЯ КОМАНД)
ЛЕКЦИЯ 10
1)Структуры с горизонтальным кодированием Где каждый разряд операционного поля указывает на наличие 1 или отсутствие 0 микрооперации. Достоинства: возможность одновременного выполнения микроопераций в одном такте. Недостаток: большая разрядность микрокоманд. 2)Вертикальное кодирование Операционное поле представляет двоичный код микрокоманды. При количестве m разрядов общее число микроопераций =2m. Недостаток- возможно выполнение только одной микрооперации в такте
Горизонтально-вертикальное кодирование(гибрид двух способов).
ВЕРТИКАЛЬНО-ГОРИЗОНТАЛЬНЫЙ СПОСОБ КОДИРОВАНИЯ
Блок управления с жесткой логикой.

СХЕМА ПРОГРАММИРУЕМОЙ ЛОГИЧЕСКОЙ МАТРИЦЫ
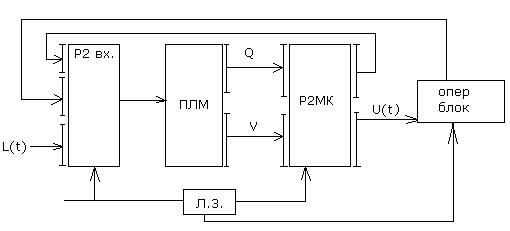
ИСПОЛЬЗОВАНИЕ ПЛМ В БЛОКЕ УПРАВЛЕНИЯ С ЖЕСТКОЙ ЛОГИКОЙ
ЛЕКЦИЯ 11
Конвейерная обработка команд(блок предсказания перехода)
Двухбитная схема предсказания перехода
ЦЕНТРАЛИЗОВАННАЯ СХЕМА УПРАВЛННИЯ
Метод переименования регистров (пример) Предположим, что необходимо вычисление (x + y)c x = ix1 + jy2; x + y=i(x1+x2) + j(y1+y2) y=ix2 + jy2; c(x + y)=ic(x1+x2) + c(y1+y2)j Т.е. значение координаты нового вектора: c(x1+x2), c(y1+y2) которые будут помещены в регистровый файл. Данные вычисления будут производиться на суперскалярном процессоре имеющегот 2 конвейера: конвейер с фиксированной точкой (операции сложения) и конвейер умножения (множительное устройство) Программа для выполнения: ADD R5=R1+R2 MUL R6=R0*R5 ADD R5=R3+R4 MUL R7=R0*R5 Общая схема:
R7 R6 R5
R11 X1 R2 X2 R3 Y1 R4 Y2 R0 C
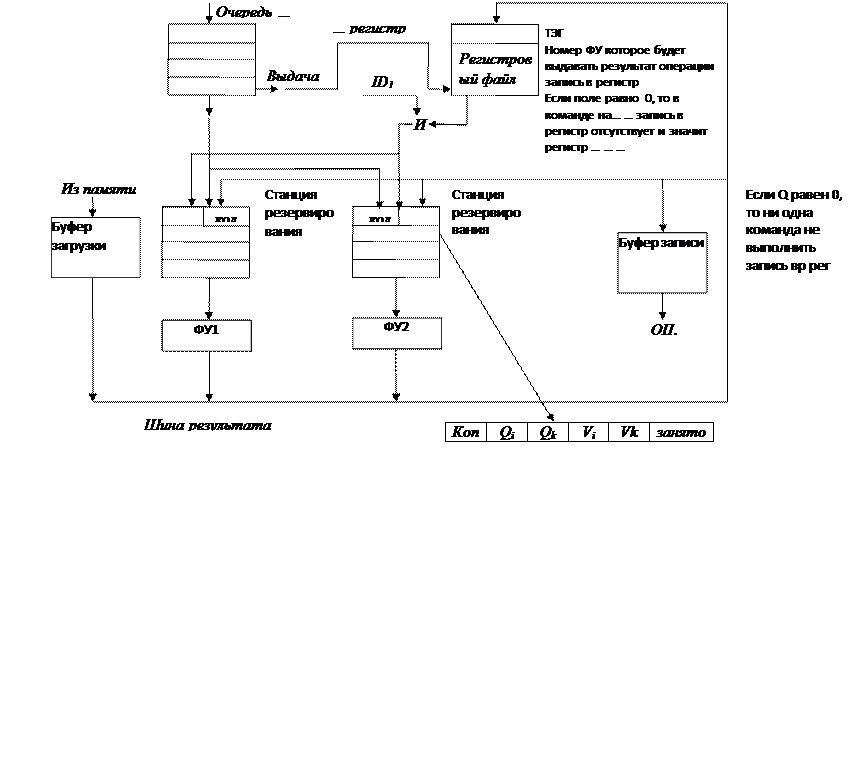
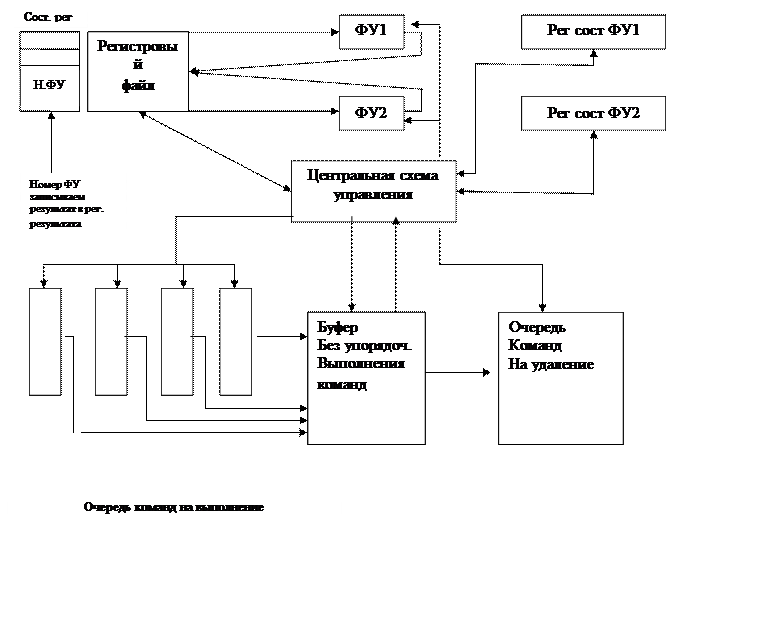
БЛОК-СХЕМА БЕЗУПОРЯДОЧНОГО ВЫПОЛНЕНИЯ КОМАНД
да нет
ID2- чтен
EX-выполнение
Регистр состояния ФУ
Для многофункциональных устройств
  Входная очередь шина Входная очередь шина
 
Буфер переупорядочения
Архитектура POWER 4.
|





























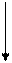



 КЛАССИФИКАЦИЯ ПАМЯТИ В ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЕ
КЛАССИФИКАЦИЯ ПАМЯТИ В ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЕ


















 +
+  - емкость субмодуля
- емкость субмодуля




 e
e

 Старшие
Старшие







 Блок-схема регенерации памяти
Блок-схема регенерации памяти





 ,
,  ,
, 



 CPBB
CPBB CPBC
CPBC


















 БЛОК-СХЕМА МИКРОПРОГРАММНОГО УПРАВЛЕНИЯ
БЛОК-СХЕМА МИКРОПРОГРАММНОГО УПРАВЛЕНИЯ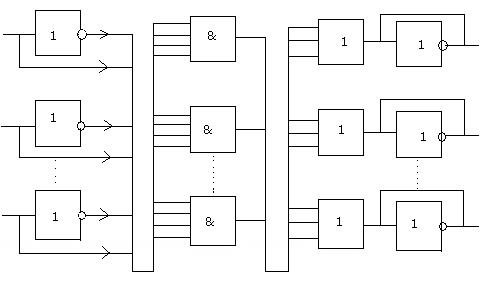















 2.R6=R0*R5 ID EX W запись 2-ой команды
2.R6=R0*R5 ID EX W запись 2-ой команды


 3.R5=R3+R4
3.R5=R3+R4 регистр R5 ЗАНЯТ 2ой командой запись не возможна
регистр R5 ЗАНЯТ 2ой командой запись не возможна
 4.R7=R0*R5
4.R7=R0*R5



 ID EX EX W RAW конфликт поR5 между 1и 2 командами
ID EX EX W RAW конфликт поR5 между 1и 2 командами








 5.R5=R1+R2
5.R5=R1+R2

 6.R6=R0*R5 ID EX W как видно из примера переименование регистров
6.R6=R0*R5 ID EX W как видно из примера переименование регистров 7.S1=R3+R4 ID EX W увеличивает производительность работы конвейера
7.S1=R3+R4 ID EX W увеличивает производительность работы конвейера
 ID EX EX W
ID EX EX W

 ID EX EX W
ID EX EX W


 Да нет ID1-выдача
Да нет ID1-выдача



 конфликтWAW
конфликтWAW




 Да нет нет
Да нет нет







 Структурная схема без упорядоченного выполнения с блоком предсказывания переходов
Структурная схема без упорядоченного выполнения с блоком предсказывания переходов







 Станции резервирования
Станции резервирования







 Строка станции резервирования
Строка станции резервирования СDВ
СDВ

 Буфер переупор.
Буфер переупор.



























