| ПОЗНАВАТЕЛЬНОЕ Сила воли ведет к действию, а позитивные действия формируют позитивное отношение Как определить диапазон голоса - ваш вокал Игровые автоматы с быстрым выводом Как самому избавиться от обидчивости Противоречивые взгляды на качества, присущие мужчинам Вкуснейший "Салат из свеклы с чесноком" Натюрморт и его изобразительные возможности Применение, как принимать мумие? Мумие для волос, лица, при переломах, при кровотечении и т.д. Как научиться брать на себя ответственность Зачем нужны границы в отношениях с детьми? Световозвращающие элементы на детской одежде Как победить свой возраст? Восемь уникальных способов, которые помогут достичь долголетия Классификация ожирения по ИМТ (ВОЗ) Глава 3. Завет мужчины с женщиной
Оси и плоскости тела человека - Тело человека состоит из определенных топографических частей и участков, в которых расположены органы, мышцы, сосуды, нервы и т.д.
| Сканирование слева направо, сравнение справа налево.
Алгоритм Бойера — Мура Данный алгоритм был разработан двумя учеными — Робертом Бойером (англ. Robert Stephen Boyer) и Джеем Муром (англ. J Strother Moore) в 1977 году. Он считается наиболее быстрым среди алгоритмов общего назначения, предназначенных для поиска подстроки в строке.
Примечание: Вопрос: что значит алгоритмы «общего назначения»? Ответ: это значит, что эти алгоритмы универсальны, т.е. предназначены для решения широкого класса задач.
Ключевые понятия: Алфавит — конечное множество символов. Подстрока — это последовательность подряд идущих символов в строке. Строка — последовательность символов текста. Суффикс — это подстрока, заканчивающаяся на последний символ строки.
Примечание: В определении строки речь не обязательно должна идти именно о тексте. В общем случае строка — это любая последовательность байтов. Поиск подстроки в строке осуществляется по заданному образцу, т. е. некоторой последовательности байтов, длина которой не превышает длину строки. Наша задача заключается в том, чтобы определить, содержит ли строка заданный образец.
Описание: Алгоритма Бойера — Мура можно представить в виде двух простых шагов.
1 шаг Для искомого образца строим две таблицы — таблицу стоп-символов и таблицу суффиксов.
Примечание: Процесс построения таблиц будет описан ниже.
2 шаг Совмещаем начало строки и образца и начинаем проверку с последнего символа образца.
Если символы совпадают, производится сравнение предпоследнего символа образца и т. д. Если все символы образца совпали с наложенными символами строки, значит, подстрока найдена и поиск окончен.
Если же какой-то символ образца не совпадает с соответствующим символом строки, образец сдвигается на несколько символов вправо, и проверка снова начинается с последнего символа.
Назовем эти «несколько символов», упомянутые в предыдущем абзаце, величиной сдвига. В качестве величины сдвигаберется большее из двух значений:
1) Значение, полученное с помощью таблицы стоп-символов по простому правилу: Если несовпадение произошло на позиции
Примечание:
2) Значение, полученное из таблицы суффиксов.
Подробное описание работы алгоритма Псевдокод: алгоритм Бойера — Мура Boyer-Moore-Matcher( 1. 2. m 3. 4. 5. 6. while 7. do 8. while 9. do 10. if 11. then print «Образец входит со сдвигом» s 12. 13. else Алгоритм основан на трёх идеях.
Сканирование слева направо, сравнение справа налево. Совмещается начало текста (строки) и шаблона, проверка начинается с последнего символа шаблона. Если символы совпадают, производится сравнение предпоследнего символа шаблона и т. д. Если все символы шаблона совпали с наложенными символами строки, значит, подстрока найдена, и поиск окончен. Если же какой-то символ шаблона не совпадает с соответствующим символом строки, шаблон сдвигается на несколько символов вправо, и проверка снова начинается с последнего символа.
Примечание: Эти «несколько», упомянутые в предыдущем абзаце, вычисляются по двум эвристикам.
Вопрос: что такое эвристика? Ответ: эвристика — это не полностью математически обоснованный (или даже «не совсем корректный»), но при этом практически полезный алгоритм.
2. Эвристика стоп-символа(англ. bad-character heuristic). Стоп-символ — это первый справа символ в строке, отличный от соответствующего символа в образце. Эвристика стоп-символа предлагает попробовать новое значение сдвига, исходя из того, где в образце встречается стоп-символ (если вообще встречается).
В наиболее удачном случае стоп-символ выявляется при первом же сравнении и не встречается нигде в образце. В этом случае сдвиг можно сразу увеличить на Если этот наиболее удачный случай повторяется постоянно, то при поиске подстроки мы просмотрим всего лишь
В общем случае эвристика стоп-символа работает так. Предположим, что при сравнении права налево мы наткнулись на первое несовпадение:
В самом деле, если Если Наконец, если
Чтобы применять эвристику стоп-символа полезно для каждого возможного стоп-символа
Псевдокод: найти последнее вхождение стоп-символа в подстроку Compute-Last-Occurrence-Function( 1. for each character 2. do 3. for 4. do 5. return
Примечание: Время работы процедуры Compute-Last-Occurrence-Function есть
Пример использования эвристики стоп-символа: Предположим, что мы производим поиск слова «колокол». Первая же буква не совпала — «к» (назовём эту букву стоп-символом). Тогда можно сдвинуть шаблон вправо до последней буквы «к». ! Строка: * * * * * * к * * * * * * Шаблон: к о л о к о л Следующий шаг: к о л о к о л
Если стоп-символа в шаблоне вообще нет, шаблон смещается за этот стоп-символ. ! Строка: * * * * * а л * * * * * * * * Шаблон: к о л о к о л Следующий шаг: к о л о к о л
В данном случае стоп-символ — «а», и шаблон сдвигается так, чтобы он оказался прямо за этой буквой. В алгоритме Бойера — Мура эвристика стоп-символа вообще не смотрит на совпавший суффикс (см. ниже), так что первая буква шаблона («к») окажется под «л», и будет проведена одна заведомо холостая проверка.
Если стоп-символ «к» оказался за другой буквой «к», эвристика стоп-символа не работает. ! Строка: * * * * к к о л * * * * * Шаблон: к о л о к о л Следующий шаг: к о л о к о л ?????
В таких ситуациях выручает третья идея алгоритма — эвристика совпавшего суффикса.
3. Эвристика безопасного (совпавшего) суффикса(англ. good-suffix heuristic). Если
Эвристика безопасного суффикса состоит в следующем: если
Иными словами,
Псевдокод: вычисление функции безопасных суффиксов Compute-Good-Suffix-Function( 1. m = length(P) 2. pi[] = префикс-функция(P) 3. pi1[] = префикс-функция(обращение(P)) 4. for j=0..m 5. suffshift[j] = m - pi[m] 6. for i=1..m 7. j = m - pi1[i] 8. suffshift[j] = min(suffshift[j], i - pi1[i]) Примечание: Время работы процедуры Compute-Good-Suffix-Function есть
Пример использования эвристики безопасного (совпавшего) суффикса: Если при сравнении строки и шаблона совпало один или больше символов, шаблон сдвигается в зависимости от того, какой суффикс совпал. Строка: * * т о к о л * * * * * Шаблон: к о л о к о л Следующий шаг: к о л о к о л
В данном случае совпал суффикс «окол», и шаблон сдвигается вправо до ближайшего «окол». Если подстроки «окол» в шаблоне больше нет, но он начинается на «кол», сдвигается до «кол», и т. д.
Обе эвристики требуют предварительных вычислений — в зависимости от шаблона поиска заполняются две таблицы. Таблица стоп-символов по размеру соответствует алфавиту (например, если алфавит состоит из 256 символов, то её длина 256); таблица суффиксов — искомому шаблону. Именно из-за этого алгоритм Бойера — Мура не учитывает совпавший суффикс и несовпавший символ одновременно — это потребовало бы слишком много предварительных вычислений.
Опишем подробнее обе таблицы.
Таблица стоп-символов Считается, что символы строк нумеруются с 1 (как в Паскале).
В таблице стоп-символов указывается последняя позиция в образце Например, если Символ a b c d [все остальные] Последняя позиция 5 2 7 6 0
Обратите внимание, для стоп-символа «d» последняя позиция будет 6, а не 8 — последняя буква не учитывается. Это известная ошибка, приводящая к неоптимальности. Для АБМ она не фатальна («вытягивает» эвристика суффикса), но фатальна для упрощённой версии АБМ — алгоритма Хорспула.
Если несовпадение произошло на позиции
Таблица суффиксов Для каждого возможного суффикса Суффикс [пустой] d cd dcd ... abcdadcd Сдвиг 1 2 4 8 ... 8 Иллюстрация было ? ?d ?cd ?dcd ... abcdadcd стало abcdadcd abcdadcd abcdadcd abcdadcd ... abcdadcd
Если шаблон начинается и заканчивается одной и той же комбинацией букв, Например, для
Суффикс [пустой] л ол ... олокол колокол Сдвиг 1 4 4 ... 4 4 Иллюстрация было ? ?л ?ол ... ?олокол колокол стало колокол колокол колокол ... колокол колокол Пример: Пусть у нас есть набор символов (алфавит) из пяти символов:
1 шаг Таблица стоп-символов
Если несовпадение произошло на позиции Таблица суффиксов для образца “ Суффикс [пустой] d ad bad bbad abbad Сдвиг 1 5 5 5 5 5 Иллюстрация было ? ?d ?ad ?bad ?bbad abbad стало abbad abbad abbad abbad abbad abbad
2 шаг a b e c c a a b a d b a b b a d a b b a d
Накладываем образец на строку. Совпадения суффикса нет — таблица суффиксов даёт сдвиг на одну позицию. Для несовпавшего символа исходной строки «с» (5-я позиция) в таблице стоп-символов записан 0. Сдвигаем образец вправо на 5-0=5 позиций: a b e c c a a b a d b a b b a d a b b a d
Символы 3—5 совпали, а второй — нет. Эвристика стоп-символа для «а» не работает (2-4=-2). Но поскольку часть символов совпала, в дело включается эвристика совпавшего суффикса, сдвигающая образец сразу на пять позиций! a b e c c a a b a d b a b b a d a b b a d
И снова совпадения суффикса нет. В соответствии с таблицей стоп-символов сдвигаем образец на 1 позицию и получаем искомое вхождение образца: a b e c c a a b a d b a b b a d a b b a d
Вычислительная сложность Общая оценка вычислительной сложности алгоритма —
Время исполнения алгоритма Бойера — Мура в наихудшем случае есть Выводы Достоинства
Алгоритм Бойера-Мура на «хороших» данных очень быстр, а вероятность появления «плохих» данных крайне мала. Поэтому он оптимален в большинстве случаев, когда нет возможности провести предварительную обработку текста, в котором проводится поиск (haystack). Разве что на коротких текстах выигрыш не оправдает предварительных вычислений.
Примечание: haystack — строка, в которой выполняется поиск. В переводе на русский haystack дословно означает «стог сена».
Недостатки
Алгоритмы семейства Бойера — Мура не расширяются до приблизительного поиска, поиска любой строки из нескольких.
Сравнение не является «чёрным ящиком», поэтому при реализации наиболее быстрого поиска приходится либо рассчитывать на удачную работу оптимизатора, либо вручную оптимизировать поиск на ассемблерном уровне.
Если текст изменяется редко, а операций поиска проводится много (например, поисковая машина), в тексте стоило бы провести индексацию, после чего поиск можно будет выполнять в разы быстрее, чем даже алгоритмом Бойера — Мура.
На больших алфавитах (например, Юникод) таблица стоп-символов может занимать много памяти. В таких случаях либо обходятся хэш-таблицами, либо дробят алфавит, рассматривая, например, 4-байтовый символ как пару двухбайтовых.
На искусственно подобранных «неудачных» текстах (например,
Итог Алгоритм Бойера и Мура оптимален в большинстве случаев, когда нет возможности провести предварительную обработку текста, в котором проводится поиск. Особенность алгоритма Бойера и Мура заключается в предварительных вычислениях над подстрокой с целью сравнения подстроки с исходной строкой, осуществляемой не во всех позициях.
Источники: http://ru.wikipedia.org/wiki/Алгоритм_Бойера_—_Мура http://www.rsdn.ru/article/alg/textsearch.xml http://www.intuit.ru/department/algorithms/staldata/39/2.html#image.39.3 Кормен Т., Лейзерсон Ч., Ривест Р. "Алгоритмы: построение и анализ".-М.:МЦНМО,1999, с.801 – 806 |



 , а стоп-символ «
, а стоп-символ «  », то значение величины сдвига будет равно
», то значение величины сдвига будет равно 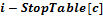 .
. - позиция символа в образце (нумерация с 1);
- позиция символа в образце (нумерация с 1); — значение, записанное в таблице стоп-символов, для символа «c».
— значение, записанное в таблице стоп-символов, для символа «c». )
)

 Compute-Last-Occurrence-Function(
Compute-Last-Occurrence-Function(  )
) Compute-Good-Suffix-Function(
Compute-Good-Suffix-Function(  )
)


 and
and 


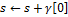

 : любой меньший сдвиг заведомо не подойдет, так как стоп- символ в тексте окажется напротив какого-то символа из образца.
: любой меньший сдвиг заведомо не подойдет, так как стоп- символ в тексте окажется напротив какого-то символа из образца.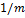 часть текста (вот как полезно сравнивать справа налево!).
часть текста (вот как полезно сравнивать справа налево!). , где
, где  . Пусть
. Пусть  — номер самого правого вхождения символа
— номер самого правого вхождения символа  в образец
в образец  (если этот символ вообще не появляется в образце, считаем
(если этот символ вообще не появляется в образце, считаем  ). Мы утверждаем, что можно увеличить
). Мы утверждаем, что можно увеличить  на
на  , не упустив ни одного допустимого сдвига.
, не упустив ни одного допустимого сдвига. , то стоп-символ
, то стоп-символ  позиций вправо.
позиций вправо. , то образец можно сдвинуть на
, то образец можно сдвинуть на  , то эвристика предлагает сдвигать образец не вправо, а влево; алгоритм Бойера — Мура эту рекомендацию игнорирует, поскольку эвристика безопасного суффикса всегда предлагает ненулевой сдвиг вправо.
, то эвристика предлагает сдвигать образец не вправо, а влево; алгоритм Бойера — Мура эту рекомендацию игнорирует, поскольку эвристика безопасного суффикса всегда предлагает ненулевой сдвиг вправо. вычислить значение
вычислить значение  — номер крайнего правого вхождения
— номер крайнего правого вхождения  в
в  , как и написано в строке 13 алгоритма Boyer-Moore-Matcher.
, как и написано в строке 13 алгоритма Boyer-Moore-Matcher.

 to
to 



 и
и  — строки, будем говорить, что они сравнимы (обозначение:
— строки, будем говорить, что они сравнимы (обозначение:  ), если одна из них является суффиксом другой. Если выровнять две сравнимые строки по правому краю, то символы, расположенные один под другим, будут совпадать. Отношение
), если одна из них является суффиксом другой. Если выровнять две сравнимые строки по правому краю, то символы, расположенные один под другим, будут совпадать. Отношение  симметрично: если
симметрично: если 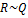 .
. (и число
(и число  — наибольшее с таким свойством), то мы можем безбоязненно увеличить сдвиг на
— наибольшее с таким свойством), то мы можем безбоязненно увеличить сдвиг на
 — наименьшее расстояние, на которое мы можем сдвинуть образец без того, чтобы какой- то из символов, входящих в «безопасный суффикс»
— наименьшее расстояние, на которое мы можем сдвинуть образец без того, чтобы какой- то из символов, входящих в «безопасный суффикс»  оказался напротив несовпадающего с ним символа из образца. Поскольку строка
оказался напротив несовпадающего с ним символа из образца. Поскольку строка  заведомо сравнима с пустой строкой
заведомо сравнима с пустой строкой  , число
, число  для всех
для всех  функцией безопасного суффикса (англ. good-suffix function), ассоциированной со строкой
функцией безопасного суффикса (англ. good-suffix function), ассоциированной со строкой 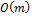 .
. , таблица стоп-символов будет выглядеть так.
, таблица стоп-символов будет выглядеть так.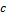 , то сдвиг будет
, то сдвиг будет  .
. шаблона
шаблона  (в обеих системах нумерации). Например, для того же
(в обеих системах нумерации). Например, для того же  для всех суффиксов (кроме, естественно, пустого) сдвиг будет равен 4.
для всех суффиксов (кроме, естественно, пустого) сдвиг будет равен 4. и мы хотим найти вхождение образца “
и мы хотим найти вхождение образца “  ” в строке “
” в строке “  ”. Следующие схемы иллюстрируют все этапы выполнения алгоритма:
”. Следующие схемы иллюстрируют все этапы выполнения алгоритма: на непериодических шаблонах и
на непериодических шаблонах и  на периодических, где n — строка, в которой выполняется поиск, m — шаблон поиска, Σ — алфавит, на котором проводится сравнение. В 1991 году Коул показал, что на непериодических шаблонах за полный проход по строке алгоритм совершит не более
на периодических, где n — строка, в которой выполняется поиск, m — шаблон поиска, Σ — алфавит, на котором проводится сравнение. В 1991 году Коул показал, что на непериодических шаблонах за полный проход по строке алгоритм совершит не более  сравнений.
сравнений. , поскольку на исполнение Compute-Last-Occurrence-Function уходит время
, поскольку на исполнение Compute-Last-Occurrence-Function уходит время  , на Compute-Good-Suffix-Function уходит
, на Compute-Good-Suffix-Function уходит  , и в худшем случае алгоритм Бойера — Мура (как и алгоритм Рабина — Карпа) потратит время
, и в худшем случае алгоритм Бойера — Мура (как и алгоритм Рабина — Карпа) потратит время  ) скорость алгоритма Бойера — Мура серьёзно снижается. Существуют попытки совместить присущую алгоритму Кнута — Морриса — Пратта эффективность в «плохих» случаях и скорость Бойера — Мура в «хороших» — например, турбо-алгоритм, обратный алгоритм Колусси и другие.
) скорость алгоритма Бойера — Мура серьёзно снижается. Существуют попытки совместить присущую алгоритму Кнута — Морриса — Пратта эффективность в «плохих» случаях и скорость Бойера — Мура в «хороших» — например, турбо-алгоритм, обратный алгоритм Колусси и другие.