| ПОЗНАВАТЕЛЬНОЕ Сила воли ведет к действию, а позитивные действия формируют позитивное отношение Как определить диапазон голоса - ваш вокал Игровые автоматы с быстрым выводом Как самому избавиться от обидчивости Противоречивые взгляды на качества, присущие мужчинам Вкуснейший "Салат из свеклы с чесноком" Натюрморт и его изобразительные возможности Применение, как принимать мумие? Мумие для волос, лица, при переломах, при кровотечении и т.д. Как научиться брать на себя ответственность Зачем нужны границы в отношениях с детьми? Световозвращающие элементы на детской одежде Как победить свой возраст? Восемь уникальных способов, которые помогут достичь долголетия Классификация ожирения по ИМТ (ВОЗ) Глава 3. Завет мужчины с женщиной
Оси и плоскости тела человека - Тело человека состоит из определенных топографических частей и участков, в которых расположены органы, мышцы, сосуды, нервы и т.д.
| Понятие и назначение используемых в работе информационных технологий
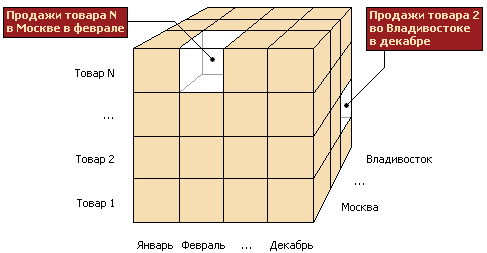
ИТ[4] (информационные технологии) – процессы, методы поиска, сбора, хранения, переработки, предоставления, распространения информации и способы осуществления этих процессов и методов. В современных информационных технологиях выделяют 3 составляющие: - аппаратное обеспечение (средства вычислительной техники и оргтехники - hardware); - программное обеспечение (прикладное и системное программное обеспечение, методическое и информационное обеспечение - software); - организационное обеспечение (включая человека в системы информационных технологий, взаимодействие человека с этими системами, системное использование технических и программных средств - orgware). При этом ИТ присущи следующие свойства: - высокая степень деления процесса на стадии - системная целостность процесса, который должен включать весь набор элементов, обеспечивающих необходимую завершенность действий человека при достижении поставленной цели - регулярность процесса и однозначность его фаз, позволяющие применять средние величины при их характеристике, и, следовательно, допускающие их унификацию и стандартизацию процессов. Различают следующие виды информационных технологий: o Глобальные (модели, методы, средства, формирующие информационные ресурсы общества) o Базовые (используются в определенной области: производство, наука, обучение) o Специальные (реализуют решение конкретных функциональных задач пользователя) Далее следует рассмотреть теоретические основы технологий сбора, трансформации, загрузки и обработки данных (ETL, Data Mining, KDD). ETL (от англ. Extract, Transform, Load — дословно «извлечение, преобразование, загрузка») — один из основных процессов в управлении ХД, который включает в себя: · извлечение данных из внешних источников · их трансформация и очистка, чтобы они соответствовали нуждам бизнес-модели · загрузка их в хранилище данных Изначально ETL-системы использовались для переноса информации из более ранних версий различных информационных систем в более новые. В настоящее время они находят все более широкое применение именно для консолидации данных с целью их дальнейшего анализа. Очевидно, что поскольку ХД могут строиться на основе различных моделей данных (многомерных, реляционных, гибридных), то и процесс ETL должен разрабатываться с учетом всех особенностей используемой в ХД модели. Все операции над данными в процессе ETL производятся в так называемой промежуточной области, где для этого создаются временные таблицы. OLAP - категория приложений и технологий, которые обеспечивают сбор, хранение, манипулирование и анализ многомерных данных. Анализируемая информация представляется в виде многомерных кубов, где измерениями служат показатели исследуемого процесса, а в ячейках содержатся агрегированные данные (рис.2)
Рисунок 2 – Пример многомерного гиперкуба Первоначально было указано 12 правил OLAP, которые определяли эту технологию, в настоящее время этот список расширили до 18 главных правил, но всего их около 300. Data Mining - это процесс обнаружения в "сырых" данных ранее неизвестных нетривиальных практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. Data Mining является одним из шагов Knowledge Discovery in Databases. Найденные знания должны быть применимы и на новых данных с некоторой степенью достоверности. Полезность заключается в том, что эти знания могут приносить определенную выгоду при их применении. Знания должны быть в понятном для пользователя не математика виде. Алгоритмы, используемые в Data Mining, требуют большого количества вычислений. Раньше это являлось сдерживающим фактором широкого практического применения Data Mining, однако сегодняшний рост производительности современных процессоров снял остроту этой проблемы. Теперь за приемлемое время можно провести качественный анализ сотен тысяч и миллионов записей. Задачи, решаемые методами Data Mining: 1. Классификация – это отнесение объектов (наблюдений, событий) к одному из заранее известных классов. 2. Регрессия. Установление зависимости непрерывных выходных от входных переменных. 3. Кластеризация – это группировка объектов на основе данных (свойств), описывающих сущность этих объектов. Объекты внутри кластера должны быть "похожими" друг на друга и отличаться от объектов, вошедших в другие кластеры. Чем больше похожи объекты внутри кластера и чем больше отличий между кластерами, тем точнее кластеризация. 4. Ассоциация – выявление закономерностей между связанными событиями. 5. Последовательные шаблоны – установление закономерностей между связанными во времени событиями, т.е. обнаружение зависимости, что если произойдет событие X, то спустя заданное время произойдет событие Y. 6. Анализ отклонений – выявление наиболее нехарактерных шаблонов. KDD-технология - это процесс поиска полезных знаний в данных. KDD включает в себя вопросы: подготовки данных, выбора информативных признаков, очистки, применения методов Data Mining, постобработки и интерпретации полученных результатов. Deductor содержит все необходимые инструменты для реализации KDD-процесса:
Реализация в Deductor KDD-подхода позволяет решать задачу формализации знаний экспертов и их тиражирования. Конечные пользователи могут не задумываться, как получены те или иные результаты, система автоматически извлечет необходимые для анализа данные, выполнит подготовленный сценарий и отобразит результаты наиболее удобным для конечного пользователя способом. |