| ПОЗНАВАТЕЛЬНОЕ Сила воли ведет к действию, а позитивные действия формируют позитивное отношение Как определить диапазон голоса - ваш вокал Игровые автоматы с быстрым выводом Как самому избавиться от обидчивости Противоречивые взгляды на качества, присущие мужчинам Вкуснейший "Салат из свеклы с чесноком" Натюрморт и его изобразительные возможности Применение, как принимать мумие? Мумие для волос, лица, при переломах, при кровотечении и т.д. Как научиться брать на себя ответственность Зачем нужны границы в отношениях с детьми? Световозвращающие элементы на детской одежде Как победить свой возраст? Восемь уникальных способов, которые помогут достичь долголетия Классификация ожирения по ИМТ (ВОЗ) Глава 3. Завет мужчины с женщиной
Оси и плоскости тела человека - Тело человека состоит из определенных топографических частей и участков, в которых расположены органы, мышцы, сосуды, нервы и т.д.
| Построение семантической сети 12
Краткие теоретические сведения Статистическая компьютерная обработка текста полезна для решения задач, связанных с выделением в тексте ключевых слов и выражений, оценкой тематики и уровня сложности текста. Также потребность в подобных программах возникает, если переводчики не пользуются программами переводческой памяти, но требуется отслеживать употребление и перевод ключевых терминов.
Wordstat (распространяется бесплатно). Пользоваться программой предельно просто - выбираете файл (правда, поддерживаются только форматы txt и html\htm), нажимаете на кнопку
и получаете файл - опять в формате txt - с ключевыми словами:
Как можно заметить по результатам, алгоритм программы также предельно прост: программа считает количество употреблений каждого слова, и на основании этих данных строит свой список-рейтинг. В результате - на первое место попадают предлоги, союзы, артикли - совсем не то, что в действительности несет важную информацию. К тому же, слова анализируются только "в розницу" - это минус, ведь в глоссарий ключевых терминов нужно включать и словосочетания. TextAnalyst (распространяется бесплатно) Программа построения семантической сети понятий, выделяемых из обрабатываемого текста, со ссылками на контекст. Позволяет анализировать текст путем построения иерархического дерева тем/подтем, затрагиваемых в тексте. Также имеется возможность реферирования текста. Лингвистический анализ проводится в основном на основе стемминга. Морфологический анализ реализован для сравнительно небольшого количества слов. Из лингвистического анализа исключаются не только стоп-слова, но и все глаголы. При поиске не учитывается порядок слов. Синтаксический и семантический машинный анализ тестов не реализован. SDK реализует функции лемматизации для русского и английского языков, построения частотных списков понятий, поиска слов в контексте. TextAnalyst Lib реализует создание гипертекстовых связей выявляемых понятий. TextAnalyst обладает более совершенным алгоритмом, учитывающим, наряду с частотностью, целый ряд лингвистических параметров: положение слова в предложении, положение предложения в тексте, связь слов между собой, семантические параметры.
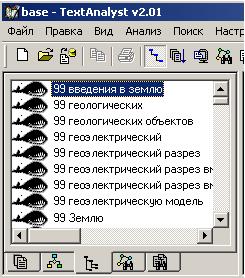
И, хотя в результатах получается много "шума", важные термины действительно выделяются и могут быть использованы для создания глоссария ключевых слов. Программа поддерживает только русский язык. Построение семантической сети Прежде всего, изучив предложенный материал, TextAnalyst формирует семантическую сеть - интегральное представление смысла текста, служащее основой для всех видов дальнейшего анализа. Семантическая сеть - это множество понятий текста - слов и словосочетаний, связанных между собой по смыслу. В семантическую сеть включены не все слова текста, а лишь наиболее значимые, несущие основную смысловую нагрузку. При этом в сеть не входят обще употребимые слова, а также слова, очень редко встречавшиеся в тексте (этот параметр - частоту встречаемости, вы сможете настраивать по своему желанию). Поэтому, с одной стороны семантическая сеть достаточно точно представляет смысл текстов, а с другой позволяет отбросить несущественную информацию. Содержание предстает в агрегированном виде, так называемым смысловым портретом. При этом каждое понятие, многократно повторявшееся в различных местах текстов, представляется в сети единственным элементом. Для отображения в один элемент сети различные формы слов, приводятся к общей грамматической форме. К каждому понятию сети предлагается список других понятий, в сочетании с которыми оно встречалось в предложения текста, а также список всех предложений, в которых понятия употреблялось. Таким образом, происходит аккумулирование информации, касающейся понятий, которая ранее была разбросана по всему тексту. В результате по каждому понятию - теме текста - можно увидеть сразу всю информацию, буквально бросив единственный взгляд на набор его связей в семантической сети. В результате, передвигаясь по смысловым связям от понятия к понятию, можно находить и прицельно исследовать лишь интересующие места текстов, не затрудняя себя просмотром всей имеющейся информации. Однако, это еще не все! Каждое понятие семантической сети характеризуется числовой оценкой - так называемым смысловым весом. Связи между парами понятий, в свою очередь, также имеют характеристики - веса связей. Эти оценки позволят сравнить относительный вклад различных понятий и их связей в общий смысл текста, выявить более или менее подробно проработанные темы, задать способ сортировки информации, и наконец, исследовать текстовый материал по пластам - смысловым срезам различной глубины - снимая сливки с содержания или глубоко погружаясь в детали. Семантическая сеть представляется в виде списка понятий. Щелкнув мышью на значке <+> возле выбранного понятия, вы можете раскрыть список всех понятий, связанных с ним. Щелчком мыши на значке <-> возле понятия с раскрытым списком вы закроете его обратно. Чтобы просмотреть всю информацию по интересующему понятию, щелкните мышью на первом пункте <все> раскрытого списка. В окне появятся все предложения текстов, включающие понятие. Само понятие выделяется цветом. Если же вас интересует не вся информация по понятию, а лишь та, которая касается его связи с одним из понятий раскрытого списка, щелкните мышью по второму понятию. В окне появятся все предложения текстов, в которых встречалась эта пара понятий. Оба понятия выделены цветом. Выбрав интересующее предложение в окне, просто щелкните по нему мышью - и в следующем окне появится соответствующий фрагмент исходного текста. Обратите внимание на числа в сети, стоящие рядом с понятиями. Ближайшее к понятию число представляет его смысловой вес. Значение варьируется от 1 до 100 и отражает важность понятия для смысла всего текста - как много информации в тексте касается данного понятия. Максимальное значение, равное 100, говорит о том, что понятие является ключевым и представляет важнейшую тему текста. Маленькое, близкое к единице значение показывает, что соответствующая тема лишь вскользь упомянута в тексте, и в тексте мало информации, относящейся к данному понятия. Второе число представляет вес связи от вершинного понятия раскрытого списка к данному понятию. Вес связей также может принимать значение от 1 до 100. Большое значение веса связи от одного понятия к другому, близкое к 100, указывает на то, что подавляющая часть информации в тексте, касающаяся первого, касается в тоже время и второго понятия - первая тема почти всегда излагается в контексте второй. Малое единичное значение отражает тот факт, что первое понятие слабо связано со вторым и очень мало информации по первой теме касается в тоже время и второй. Cвязь между парой понятий сети всегда двустороння, однако связь от первого понятия ко второму далеко не всегда имеет тот же самый вес, что и обратная, от второго к первому. Как говорится, "всякая селедка - рыба, но не всякая рыба - селедка" Вы можете настраивать вид семантической сети на экране, изменяя количество отображаемых понятий и связей, а также способ их сортировки. Для этого выберите пункт "настройка вида" в меню "вид" и установите требуемые значение параметров. Дополнительные настройки TextAnalyst позволяют вам самим задавать интересующие понятия, которые выделяются в семантической сети при анализе 12 |