| ПОЗНАВАТЕЛЬНОЕ Сила воли ведет к действию, а позитивные действия формируют позитивное отношение Как определить диапазон голоса - ваш вокал Игровые автоматы с быстрым выводом Как самому избавиться от обидчивости Противоречивые взгляды на качества, присущие мужчинам Вкуснейший "Салат из свеклы с чесноком" Натюрморт и его изобразительные возможности Применение, как принимать мумие? Мумие для волос, лица, при переломах, при кровотечении и т.д. Как научиться брать на себя ответственность Зачем нужны границы в отношениях с детьми? Световозвращающие элементы на детской одежде Как победить свой возраст? Восемь уникальных способов, которые помогут достичь долголетия Классификация ожирения по ИМТ (ВОЗ) Глава 3. Завет мужчины с женщиной
Оси и плоскости тела человека - Тело человека состоит из определенных топографических частей и участков, в которых расположены органы, мышцы, сосуды, нервы и т.д.
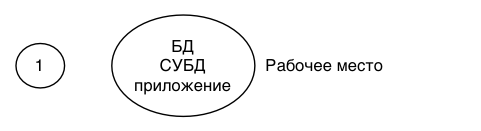
| Структура реляционной модели данныхЛокальная модель
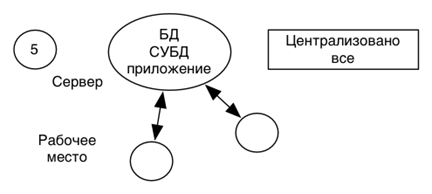
Файл-серверная модель Файл-серверные приложения — приложения, схожие по своей структуре с локальными приложениями и использующие сетевой ресурс для хранения программы и данных. Функции сервера: хранения данных и кода программы. Функции клиента: обработка данных происходит исключительно на стороне клиента. Количество клиентов ограничено десятками. Плюсы: 1. Многопользовательский режим работы с данными; 2. Удобство централизованного управления доступом; 3. Низкая стоимость разработки; Минусы: 1. Низкая производительность; 2. Низкая надежность; 3. Слабые возможности расширения; Недостатки архитектуры с файловым сервером очевидны и вытекают главным образом из того, что данные хранятся в одном месте, а обрабатываются в другом. Это означает, что их нужно передавать по сети, что приводит к очень высоким нагрузкам на сеть и, вследствие этого, резкому снижению производительности приложения при увеличении числа одновременно работающих клиентов. Вторым важным недостатком такой архитектуры является децентрализованное решение проблем целостности и согласованности данных и одновременного доступа к данным. Такое решение снижает надежность приложения.
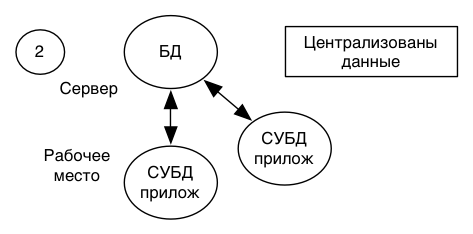
Модель удаленного доступа
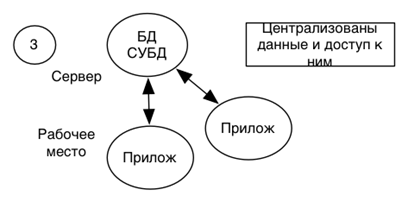
Модель сервера данных
Модель телеобработки
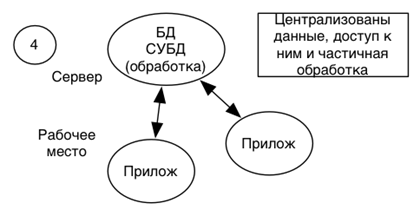
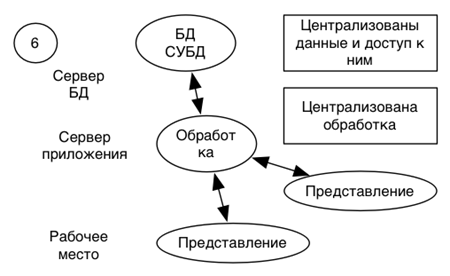
Модель сервера приложений
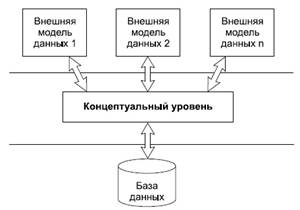
2. Архитектура базы данных. Физическая и логическая независимость Терминология в СУБД, да и сами термины "база данных" и "банк данных" частично заимствованы из финансовой деятельности. Это заимствование — не случайно и объясняется тем, что работа с информацией и работа с денежными массами во многом схожи, поскольку и там и там отсутствует персонификация объекта обработки: две банкноты достоинством в сто рублей столь же неотличимы и взаимозаменяемы, как два одинаковых байта (естественно, за исключением серийных номеров). Вы можете положить деньги на некоторый счет и предоставить возможность вашим родственникам или коллегам использовать их для иных целей. Вы можете поручить банку оплачивать ваши расходы с вашего счета или получить их наличными в другом банке, и это будут уже другие денежные купюры, но их ценность будет эквивалентна той, которую вы имели, когда клали их на ваш счет. В процессе научных исследований, посвященных тому, как именно должна быть устроена СУБД, предлагались различные способы реализации. Самым жизнеспособным из них оказалась предложенная американским комитетом по стандартизации ANSI (American National Standards Institute) трехуровневая система организации БД, изображенная на рис. 2:
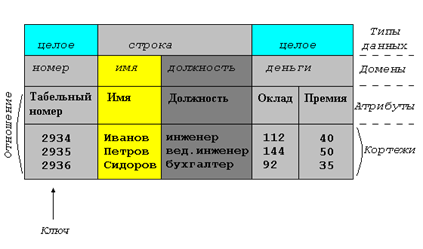
1. Уровень внешних моделей — самый верхний уровень, где каждая модель имеет свое "видение" данных. Этот уровень определяет точку зрения на БД отдельных приложений. Каждое приложение видит и обрабатывает только те данные, которые необходимы именно этому приложению. Например, система распределения работ использует сведения о квалификации сотрудника, но ее не интересуют сведения об окладе, домашнем адресе и телефоне сотрудника, и наоборот, именно эти сведения используются в подсистеме отдела кадров. 2. Концептуальный уровень — центральное управляющее звено, здесь база данных представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной базой данных. Фактически концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась база данных. Как любая модель, концептуальная модель отражает только существенные, с точки зрения обработки, особенности объектов реального мира. 3. Физический уровень — собственно данные, расположенные в файлах или в страничных структурах, расположенных на внешних носителях информации. Эта архитектура позволяет обеспечить логическую (между уровнями 1 и 2) и физическую (между уровнями 2 и 3) независимость при работе с данными. Логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с этой же базой данных. Физическая независимость предполагает возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с данной базой данных. Это именно то, чего не хватало при использовании файловых систем. Выделение концептуального уровня позволило разработать аппарат централизованного управления базой данных. 3. Модели данных. Основа информационной системы, объект ее обработки - база данных (БД). База данных- это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области или разделе предметной области. Например, база данных по вузам (высшее образование), база данных по лекарственным препаратам (медицина), база данных по автомобилям (автомагазин), база данных по стройматериалам (склад) и т.п. Синоним термина «база данных» - «банк данных». Ядром любой базы данных является модель данных, которая представляет собой структуру данных, соглашения о способах их представления и операций манипулирования ими. Иными словами, это формализованное описание объектов предметной области и взаимосвязей между ними. Различают три основных типа моделей данных: иерархическую, сетевую и реляционную. Иерархическая структура представляет собой совокупность элементов, в которой данные одного уровня подчинены данным другого уровня, а связи между элементами образуют древовидную структуру. В такой структуре исходные элементы порождают другие элементы, причем эти элементы в свою очередь порождают следующие элементы и т.д. Существенно то, что каждый порожденный элемент имеет только одного «родителя». Обратите внимание, что в иерархической структуре порождающим элементом может быть не объект сам по себе, а только конкретный экземпляр объекта. Примером иерархической базы данных может служить генеалогическое древо вашей семьи. Существуют и более сложные - сетевые структуры, в которых каждый порожденный элемент может иметь более одного порождающего элемента. Сетевая модель данных отличается от иерархической тем, что каждый элемент сетевой структуры данных связан с любым другим элементом. Примером сложной сетевой структуры может служить структура базы данных, содержащая сведения об учащихся, занимающихся в различных кружках. При этом возможны занятия одного и того же ученика в разных кружках, а также посещение несколькими учениками занятий одного кружка. Сетевые и иерархические структуры можно свести к простым двумерным таблицам. 4. Основные определения реляционной модели данных Реляционная модель данных – логическая модель данных. Впервые была предложена британским учёным сотрудником компании IBM Эдгаром Франком Коддом (E. F. Codd). В настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД. Кристофер Дейт определил три составные части реляционной модели данных: § структурная § манипуляционная § целостная Структурная часть модели определяет, что единственной структурой данных является нормализованное n-арное отношение. Отношения удобно представлять в форме таблиц, где каждая строка есть кортеж, а каждый столбец – атрибут, определенный на некотором домене. Данный неформальный подход к понятию отношения дает более привычную для разработчиков и пользователей форму представления, где реляционная база данных представляет собой конечный набор таблиц. Манипуляционная часть модели определяет два фундаментальных механизма манипулирования данными – реляционная алгебра и реляционное исчисление. Основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление. Целостная часть модели определяет требования целостности сущностей и целостности ссылок. Первое требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом. Требование целостности по ссылкам, или требование внешнего ключа состоит в том, что для каждого значения внешнего ключа, появляющегося в ссылающемся отношении, в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать). Структура реляционной модели данных Можно провести аналогию между элементами реляционной модели данных и элементами модели "сущность-связь". Реляционные отношения соответствуют наборам сущностей, а кортежи – сущностям. Поэтому, также как и в модели "сущность-связь" столбцы в таблице, представляющей реляционное отношение, называют атрибутами.
Основные компоненты реляционного отношения Каждый атрибут определен на домене, поэтому домен можно рассматривать как множество допустимых значений данного атрибута. Несколько атрибутов одного отношения и даже атрибуты разных отношений могут быть определены на одном и том же домене. В примере, показанном на рисунке, атрибуты "Оклад" и "Премия" определены на домене "Деньги". Поэтому, понятие домена имеет семантическую нагрузку: данные можно считать сравнимыми только тогда, когда они относятся к одному домену. Таким образом, в рассматриваемом нами примере сравнение атрибутов "Табельный номер" и "Оклад" является семантически некорректным, хотя они и содержат данные одного типа. Именованное множество пар "имя атрибута – имя домена" называется схемой отношения. Мощность этого множества - называют степенью или "арностью" отношения. Набор именованных схем отношений представляет из себя схему базы данных. Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). В нашем случае ключом является атрибут "Табельный номер", поскольку его значение уникально для каждого работника предприятия. Если кортежи идентифицируются только сцеплением значений нескольких атрибутов, то говорят, что отношение имеет составной ключ. Отношение может содержать несколько ключей. Всегда один из ключей объявляется первичным, его значения не могут обновляться. Все остальные ключи отношения называются возможными ключами. В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей. 5. Жизненный цикл базы данных. Этапы ЖЦ БД. Жизненный цикл базы данных — это совокупность этапов, которые проходит база данных на своём пути от создания до окончания использования.
6. Основные свойства единиц информации. Составная единица информации. Описание структуры СЕИ. Показатели Составная единица информации (СЕИ) – это набор из атрибутов и, возможно других СЕИ. Определение СЕИ рекурсивно. База данных тоже ЕИ. Множество атрибутов объединяются в одну СЕИ по следующим признакам: - соответствующие атрибуты описывают один и тот же факт или экономический процесс - значения атрибутов, входящих в СЕИ, возникают одновременно, связаны арифметическими или логическими отношениями. Простейшая характеристика СЕИ представлена именем, структурой и значением. Имя – обозначение СЕИ в процессах обработки информации Структура – вхождение одних единиц информации в состав других единиц информации. При анализе документов ставится задача разделения документа на элементарные осмысленные фрагменты, называемые показателями. Это позволяет установить смысловые взаимосвязи между различными документами, обеспечить одинаковое понимание всеми пользователями применяемых едини информации и их единое обозначение, использовать полученные результаты для определения структуры БД. Описание структуры СЕИ Для описания, не зависимого от конкретных языков программирования и СУБД, достаточно указывать после имени СЕИ список имен входящих в нее атрибутов и СЕИ. Список помещают в круглые скобки. Имя СЕИ может сопровождаться размерностью, т.е. указанием на количество одинаковых по структуре значений этой СЕИ. Размерность, если она не равна 1, указывается в скобках после имени СЕИ. Между описанием размерности и описанием структуры ставится точка. Показатель Показатель - это полное описание количественного параметра, характеризующего некоторый объект или процесс. Соответствующее описание произвольного свойства (не обязательно количественного) называется атомарным фактом. Материальные процессы имеют качественную и количественную характеристики. Соответственно разделяют атрибуты-признаки и атрибуты- основания, как информационное отображение соответственно качественного и количественного свойств некоторого объекта. В состав показателя должны входить один атрибут- основание и несколько атрибутов-признаков, однозначно характеризующих условия существования основания. Как единица информации показатель является разновидностью СЕИ. Структура показателя: П.(Р1, Р2,...,Рк, Q), где Q - атрибут-основание, Р1, Р2,...,Рк - атрибуты- признаки. Таким образом, в показателях отражаются количественные свойства объектов и процессов. Минимальный набор атрибутов показателя должен содержать: 1. Атрибуты отображающие идентификаторы объектов 2. Атрибуты, отображающие признак времени 3. Атрибут, отображающий некоторое количественное свойство объекта или взаимодействия. Для того, чтобы определить атрибут как признак или как основание можно использовать следующие закономерности: 1. Если значение атрибута является исходным данным для вычислений или результатом арифметической операции, то это основание 2. Если значение атрибута текстовое, то это признак 3. Если атрибут обозначает предмет, это признак 4. Если атрибут в некотором показателе является признаком, то он будет играть эту роль и в других показателях. 5. Если показатели описывают сходные процессы, то их призначные части совпадают. 6. Если основание показателя вычисляется по значениям других оснований, то набор признаков такого показателя есть объединение признаков, связанных с этими основаниями.
7. Операции над СЕИ: нормализация, свертка, декомпозиции, композиция, выборка, корректировка. Нормализация – операция перехода от СЕИ с произвольной структурой к СЕИ с двухуровневой структурой. Одновременно происходит перекомпоновка значений СЕИ. Общее число значений в нормализованной СЕИ равно произведению размерностей всех СЕИ в исходном описании структуры. Свёртка – это преобразование составной единицы информации с двухуровневой структурой в составную единицу информации с произвольной многоуровневой структурой. Свёртка нормализованной структуры может быть произведена в исходную в это смысле нормализация и свёртка взаимно-обратные операции. Декомпозиция – это операция преобразования исходной СЕИ в несколько СЕИ с различными структурами. Множество атрибутов СЕИ до декомпозиции должно совпадать с множеством атрибутов после декомпозиции. Композиция – это операция преобразования нескольких составных единиц информации с различными структурами в одну СЕИ. Операция композиции обратна декомпозиции и точно определяется только для нормализованных исходных составных единиц информации. Условие выполнения операции композиции двух СЕИ – это наличие атрибутов, по которым они связаны. Выборка – это операция выделения подмножества значений составной единицы информации, которая удовлетворяет заранее поставленным условиям выборки. Корректировка – это выполнение одной из следующих операций: 1. Добавление нового значения 2. Исключение существующего значения 3. Замена некоторого значения на новое Возможны более сложные режимы корректировки, например, внесение изменений в несколько СЕИ одновременно. 8. Два класса отношений: объектное и связное. Ключи отношений. Индексы. Операции над отношениями: 1. Традиционные операции (объединение, пересечение, разность, декартово произведение, деление) 2. Специальные реляционные операции (проекция, соединение, выбор) Эти операции реализуются с помощью специальных языков, которые делятся на два класса: 1. Языки реляционной алгебры, описывающие последовательность действий для получения желаемого результата 2. Языки реляционного исчисления, предоставляющие пользователю набор правил для записи запросов к БД, в которых содержится только информация о желаемом результате Различают 2 класса отношений в зависимости от содержания: 1. Объектное отношение 2. Связное отношение Объектное отношение хранит данные об объектах, или экземплярах сущности. Один из атрибутов однозначно идентифицирует каждый объект. Это первичный ключ, который может состоять из нескольких атрибутов (составной ключ) или может быть частью значения атрибута (частичный ключ). Первичный ключ должен обладать двумя свойствами: 1. Запись должна однозначно определяться значением ключа 2. Никакое поле нельзя удалить из ключа, не нарушая при этом свойства однозначной идентификации Связное отношение хранит ключи двух или более отношений, т.е. по ключам устанавливается связь между объектами отношений. Ключи в связных отношениях называются внешними, т.к. они являются первичными ключами других отношений. Реляционная модель накладывает на внешние ключи ограничение для обеспечения целостности, называемые ссылочной целостностью. Это значит, что каждому внешнему ключу должна соответствовать строка какого-либо объектного отношения, иначе окажется, что внешний ключ ссылается на неизвестный объект. Ещё одно ограничение на отношения в реляционной БД говорит о том, что каждое отношение должно иметь простые атрибуты, т.е. содержать атомарные, неделимые значения. Отношение, у которого все атрибуты простые, называется приведённым к первой нормальной форме. 9. Нормализация отношений. Требования при группировке атрибутов в отношения в реляционной БД. Нормализация – это пошаговый обратимый процесс декомпозиции, то есть разложение исходных отношений на другие более мелкие и простые отношения. При этом выясняются всевозможные функциональные зависимости между атрибутами.
Центральная задача проектирования базы данных ИС - определение количества отношений (или иных составных единиц информации) и их атрибутного состава. Задача группировки атрибутов в отношения, набор которых заранее не фиксирован, допускает множество различных вариантов решений. Рациональные варианты группировки должны учитывать следующие требования: · множество отношений должно обеспечивать минимальную избыточность представления информации, · корректировка отношений не должна приводить к двусмысленности или потере информации, · перестройка набора отношений при добавлении в базу данных новых атрибутов должна быть минимальной. Удовлетворение этих требований достигается нормализацией отношений БД.
10. Функциональные зависимости. Нормальные формы. Функциональные зависимости определяются для атрибутов, находящихся в одном и том же отношении, удовлетворяющем 1НФ. Например, пусть в отношении R1 имеются 2 атрибута А и В. Атрибут В функционально зависит от атрибута А, если в любой момент времени каждое значение атрибута А соответствует единственному значению атрибута В. Обозначается А→В (если нет зависимости, то А Если отношение находится в 1НФ, то все не ключевые атрибуты функционально зависят от ключа, но степень зависимости может быть различной. Если не ключевой атрибут зависит только от части ключа, то говорят о частичной зависимости. Если не ключевой атрибут зависит от всего составного ключа и не находится в частичной зависимости от его частей, то можно говорить о полной функциональной зависимости от составного ключа. Каждая НФ ограничена определенным типом функциональной зависимости и устраняет аномалии при выполнении Оп при рассмотрении БД. Такие частичные зависимости приводят, например, к следующим аномалиям: 1) дублирование данных о рабочем, т.к. он может произвести несколько видов деталей, и данных о деталях, поскольку каждую из них могут производить разные рабочие; 2) проблема контроля избыточности данных, т.к. изменение, например, расценки влечет за собой необходимость поиска и изменения значений расценки во всех кортежах; 3) проблема с рабочими, которые в данное время не работают (их нельзя включить в отношение, поскольку все атрибуты кортежа должны иметь определенные значения), т.е. данные о рабочем без данных о детали нельзя включить в отношение; если рабочий увольняется, то данные о нем должны быть удалены из отношения, при этом удаляются и данные о детали, а этого не должно быть.
Отношение находится в 2НФ, если оно находится в 1НФ, и каждый не ключевой атрибут функционально полно зависит от составного ключа. Чтобы устранить частичную зависимость и привести отношение ко 2НФ нужно разложить его на несколько отношений следующим образом: 1) построить проекцию без атрибутов, которые находятся в частичной зависимости от составного ключа; 2) построить проекцию на часть составного ключа и атрибуты, зависящие от этой части.
Если для атрибутов A, B,C выполняются условия A→B и B→C, но обратная зависимость отсутствует, то С зависит от А транзитивно,т.е. можно говорить о транзитивной зависимости. Наличие транзитивных зависимостей порождает неудобства и аномалии следующего характера: 1) Дублирование информации о телефоне для нескольких рабочих 2) Проблема поиска и контроля при изменении номера телефона. Таким образом, 2НФ также может требовать дальнейших преобразований. НФ Отношение находится в 3НФ, если оно находится во 2НФ и нем отсутствуют транзитивные зависимости не ключевых атрибутов от ключа. БД находится в 3НФ, если все ее отношения имеют 3НФ. Алгоритм получения 3НФ: Исходными данными для алгоритма служит некоторый список атрибутов, охватывающий одно отношение, базу данных или ее часть. В любом случае предполагается (хотя бы теоретически) существование одного отношения с заданным списком атрибутов. Алгоритм получения отношений в ЗНФ обладает следующими свойствами: • сохраняет все первоначальные функциональные зависимости, т.е. зависимость, справедливая в R, справедлива и в одном из производных отношений. Это гарантирует получение осмысленных отношений с легко интерпретируемой структурой, • обеспечивает соединение без потерь, т.е. значения исходного отношения R могут быть восстановлены из проекций отношения R с помощью операции соединения, • результат декомпозиции в ЗНФ обычно содержит меньше значений атрибутов, чем исходное отношение R (происходит уменьшение избыточности Алгоритм состоит из следующий шагов: 1)Получить исходное множество функциональных зависимостей для атрибутов рассмотренной БД. 2) Получить минимальное покрытие множества функциональных зависимостей. В частности, требуется объединить функциональные зависимости с одинаковой левой частью в одну зависимость. 3) Для каждой функциональной зависимости, полученной на 2 шаге создать проекцию исходных отношений, R[X], где X – объединение атрибутов из левой и правой частей функциональной зависимостей. 4) Если первичный ключ исходного отношения не вошел полностью ни в одну проекцию, то создаем отношение из атрибутов ключа. БКНФ (Бойса-Кодда) Считается, что отношение находится в нормальной форме БК, если оно находится в 3НФ и в нем отсутствуют зависимости ключевых атрибутов от неключевых. Отношение находится в 4НФ, если оно находится в НФБК и в нем отсутствуют многозначные зависимости не являющиеся функциональными. 5НФ. Отношение R находится в пятой нормальной форме (5НФ) тогда и только тогда, когда любая имеющаяся зависимость соединения является тривиальной. Зависимость соединения
11. Операции над отношениями: объединение, пересечение, разность, декартово произведение. Отношения В реляционной алгебре в качестве операндов выступают отношения, а основными операциями, выполняемыми над отношениями, являются: · объединение · пересечение · разность · декартово произведение · деление · проекция · соединение · выбор Введем некоторые понятия. Степенью отношения называется число входящих в него атрибутов. Мощностью (кардинальным числом) отношения называется число кортежей отношения. При выполнении некоторых операций отношения должны быть совместимыми (иметь совместимые схемы), т.е. иметь одинаковую степень и одинаковые типы соответствующих атрибутов.
ОБЪЕДИНЕНИЕ (R U S) отношений R и S представляет собой множество кортежей, которые принадлежат R или S, либо им обоим. Операция объединения выполняется над двумя совместимыми отношениями.
ПЕРЕСЕЧЕНИЕ.Результат пересечения R и S содержит только те кортежи первого отношения R, которое есть во втором S.
РАЗНОСТЬ. Результат вычитания (R-S) включает только те кортежи первого отношения R, которых нет во втором S.
ДЕКАРТОВО ПРОИЗВЕДЕНИЕ (R x T). Здесь операнды-отношения R и T могут иметь разные схемы: Степень результирующего отношения (R x T) равна сумме степеней отношений операндов (R и T), а мощность — произведение их мощностей.
12. Операции над отношениями: деление. ДЕЛЕНИЕ (R / T). Операция в некотором смысле обратна операции "декартово произведение". Отношение "делимое" (R) должно содержать подмножество атрибутов отношения "делитель" (T). Результирующее отношение (R / T) содержит только те атрибуты делимого, которых нет в делителе. В него включают только те кортежи, декартово произведение которых с делителем содержатся в делимом. 13. Операции над отношениями: проекция, выборка, соединение. ПРОЕКЦИЯ. Эта операция в отличие от всех предыдущих является унарной, т.е. выполняется над одним отношением (R). Результирующее отношение П (R) включает часть атрибутов исходного, на которые выполняется проекция. Кортежи-дубликаты отсутствуют.
СОЕДИНЕНИЕ. Операция соединения выполняется над двумя отношениями (R и S). В каждом отношении выделяется атрибут, по которому будет производиться соединение. В качестве атрибута для соединения выберем атрибут B. Результирующее отношение включает все атрибуты первого отношения (R) и второго отношения (S):
ВЫБОР. Операция выполняется над одним отношением (R). Результирующее отношение (OB=b(R)) содержит подмножества кортежей, выбранных по некоторому условию (B = b).
14. Проектирование БД (архитектура ANSI / SPARC) Архитектура ANSI-SPARC (также 3х-уровневая архитектура) определяет принцип, согласно которому рекомендуется строить системы управления базами данных(СУБД). Проект архитектуры был выдвинут в 1975 году подкомитетом SPARC ANSI. 3 уровня СУБД:
В основе архитектуры ANSI-SPARC лежит концептуальный уровень. В современных СУБД он может быть реализован при помощи представления. Концептуальный уровень описывает данные и их взаимосвязи с наиболее общей точки зрения, — концепции архитекторов базы, используя реляционную или другую модель. Внутренний уровень позволяет скрыть подробности физического хранения данных (носители, файлы, таблицы, триггеры ...) от концептуального уровня. Отделение внутреннего уровня от концептуального обеспечивает так называемую физическую независимость данных. На внешнем уровне описываются различные подмножества элементов концептуального уровня для представлений данных различным пользовательским программам. Каждый пользователь получает в свое распоряжение часть представлений о данных, но полная концепция скрыта. Отделение внешнего уровня от концептуального обеспечивает логическую независимость данных. 15. Инфологическое моделирование. Модель «сущность-связь» (ER-модель) Инфологическая модель (ИМ) - это формализованное описание естественной структуры информации предметной области, не зависящее от последующей реализации ее хранения. ER-модель (Entity-Relationship Model – модель «сущность-связь») - представление ИМ, основывающееся на структурных элементах «сущность», «свойство», «связь».
Сущности и свойства Описывает тип объекта предметной области, характеризующийся определенным набором свойств. Описывает определенную характеристику сущности. В реальности сущности соответствует множество экземпляров.
Простой объект - характеризуется набором простых единичных, безусловных свойств. Идентификатор ‐ одно или несколько свойств, по значениям которых однозначно различаются все экземпляры сущности (объекта). Простое свойство - состоит из одного компонента с независимым существованием. Составное свойство - состоит из нескольких компонентов, каждый из которых характеризуется независимым существованием. Единичное свойство - может содержать только одно значение определенного типа для любого экземпляра сущности. Множественное свойство - может содержать несколько значений определенного типа для любого экземпляра сущности. Связь - описание связанности двух сущностей и их экземпляров.
Множественность (кардинальность) указывает для каждой стороны количество экземпляров сущности, которое может быть одновременно связано с одним экземпляром другой сущности. Варианты связи по множественности: 1:1, 1:М, М:М. 1. отношение “один к одному” (1:1) означает, что каждая запись одной таблицы соответствует только одной записи в другой таблице; 2. отношение “один ко многим” (1:М) возникает, когда одна запись взаимосвязана со многими другими; 3. отношение “многие к одному” означает, что многие записи связаны с одной (М:1); 4. отношение “многие ко многим” (M:N) возникает между двумя таблицами в тех случаях, когда: · одна запись из первой таблицы может быть связана более чем с одной записью из второй таблицы; · одна запись из второй таблицы может быть связана более чем с одной записью из первой таблицы. Недостатком данной модели является то, что одни и те же элементы могут выступать одновременно и в качестве сущности, и в качестве атрибута, и в качестве связи.
Обязательность (степень участия) - указывает для каждой стороны обязательность вхождения экземпляров сущности в связь экземплярами другой сущности. Ассоциация может использоваться для: · Реализации связи М:М · Связывания трех и более сущностей · Хранения дополнительной информации о связи · Последовательность инфологического проектирования: · Определение сущностей · Установление подчиненности сущностей и формирование сложных объектов · Установление связей и определение ассоциаций · Определение свойств сущностей · Определение идентификаторов 16. Критерии оценки качества логической модели данных. Переход к реляционной модели данных (6 правил) Критерии оценки качества логической модели данных Адекватность базы данных предметной области Т.к. в реляционной модели данных между отношениями поддерживаются только связи типа «один ко многим», а в ER-модели допустимы связи «многие ко многим», то необходим специальный механизм преобразования, который позволит отразить множественные связи, неспецифические для реляционной модели, с помощью недопустимых для неё категорий. Для построения логических моделей, реляционных баз данных, методом декомпозиции, сформулирован ряд правил, получивших название «правила преобразования ER-диаграмм в отношениях БД». Правила позволяют привести схемы отношений БД к нормальным формам. Если степень связи между сущностями определена, то предварительное отношения могут быть получены путём просмотра нескольких альтернатив и выбора варианта, наиболее подходящего с точки зрения правил предметной области. Определяющими признаками выбора одного из альтернативных вариантов представления отношения и класс принадлежности сущности. Правило 1. Если степень бинарной связи 1:1 и класс принадлежности обеих сущностей является обязательным, то требуется построение только одного отношения. При этом первичным ключом отношения может быть ключ любой сущности. Правило 2. Если степень бинарной связи 1:1 и класс принадлежности одной сущности является обязательным, а другой сущности - не обязательным, то требуется построение двух отношений - по одному на каждую сущность. При этом первичным ключом каждого отношения является ключ его сущности, а ключ сущности с необязательным классом принадлежности добавляется в отношение для сущности с обязательным классом принадлежности в качестве атрибута (миграция ключа). Правило 3. Если степень бинарной связи 1:1 и класс принадлежности обеих сущностей не является обязательным, то требуется построение трех отношений - по одному на каждую объектную сущность и одному для связывающего отношения. При этом ключ каждой сущности является первичным ключом соответствующего отношения и одного отношения для связи, с первичным ключом, составленным из ключей объектных сущностей. Правило 4. Если степень бинарной связи 1:N, и класс принадлежности n-связной сущности является обязательным, то достаточно построить два отношения - по одному на каждую сущность. При этом ключ каждой сущности является первичным ключом соответствующего отношения, а ключ 1-связной сущности добавляется в отношение для n -связной сущности в качестве атрибута. Правило 5. Если степень бинарной связи 1:N и класс принадлежности n-связной сущности не является обязательным, то необходимо построить три отношения - по одному на каждую сущность. При этом ключ каждой сущности является первичным ключом соответствующего отношения и одного отношения для связи. Ключи сущностей должны быть атрибутами последнего отношения. Отметим, что если степень бинарной связи 1:N, то фактором, определяющим выбор одного из правил (правила 4, 5), является класс принадлежности n-связной сущности. Класс принадлежности 1-связной сущности не влияет на конечный результат декомпозиции. В ситуации правила 4 имеет место проблема нуль-значений по атрибуту Предмет, в ситуации правила 5 имеет место проблема нуль-значений по атрибутам Предмет и Преподаватель. Поэтому во избежание дублирования и нуль-значений в ситуации правил 4 и 5 необходимо строить два и три результирующих отношения соответственно. Миграция ключа 1-связной сущности выполняется для восстановления исходного отношения при соединении. Если степень бинарной связи N:M, то во избежание дублирования и нуль-значений необходимо всегда строить три отношения. Сформулируем шестое правило. Правило 6. Если степень бинарной связи M:N, то необходимо построить три отношения - по одному для каждой сущности и одно отношение для связи. При этом ключ каждой сущности является первичным ключом соответствующего отношения, и входит в составной первичный ключ отношения для связи.
17. Принципы поддержки целостности в реляционных моделях данных. Структурная целостность. Проблема Null значений. Под целостностью понимают соответствие информационной модели предметной области, хранимой в базе данных, объектам реального мира и их взаимосвязям в каждый момент времени. Любое изменение в предметной области, значимое для построенной модели, должно отражаться в базе данных, и при этом должна сохраняться однозначная интерпретация информационной модели в терминах предметной области. Только существенные или значимые изменения предметной области должны отслеживаться в информационной модели. Действительно, модель всегда представляет собой некоторое упрощение реального объекта, в модели мы отражаем только то, что нам важно для решения конкретного набора задач. В модели данных должны быть предусмотрены средства и методы, которые позволят нам обеспечивать динамическое отслеживание в базе данных согласованных действий, связанных с согласованным изменением информации. Поддержка целостности в реляционной модели данных в ее классическом понимании включает в себя 3 аспекта. Во-первых, это поддержка структурной целостности, которая трактуется как то, что реляционная СУБД должна допускать работу только с однородными структурами данных типа "реляционное отношение". При этом понятие "реляционного отношения" должно удовлетворять всем ограничениям, накладываемым на него в классической теории реляционной БД (отсутствие дубликатов кортежей, соответственно обязательное наличие первичного ключа, отсутствие понятия упорядоченности кортежей). В дополнение к структурной целостности необходимо рассмотреть проблему неопределенных Null значений. Как уже указывалось раньше, неопределенное значение интерпретируется в реляционной модели как значение, неизвестное на данный момент времени. Это значение при появлении дополнительной информации в любой момент времени может быть заменено на некоторое конкретное значение. При сравнении неопределенных значений не действуют стандартные правила сравнения: одно неопределенное значение никогда не считается равным другому неопределенному значению. Для выявления равенства значения некоторого атрибута неопределенному применяют специальные стандартные предикаты: <имя атрибута>IS NULL и <имя атрибута> IS NOT NULL. Если в данном кортеже (в данной строке) указанный атрибут имеет неопределенное значение, то предикат IS NULL принимает значение TRUE (Истина), а предикат IS NOT NULL — FALSE(Ложь), в противном случае предикат IS NULL принимает значение FALSE, а предикат IS NOT NULL принимает значение TRUE. Ведение Null значений вызвало необходимость модификации классической двузначной логики и превращения ее в трехзначную. Все логические операции, производимые с неопределенными значениями, подчиняются этой логике в соответствии с заданной таблицей истинности. Таблица 8.1.Таблица истинности для логических операций с неопределенными значениями
В стандарте SQL2 появилась возможность сравнивать не только конкретные значения атрибутов с неопределенным значением, но и результаты логических выражений сравнивать с неопределенным значением, для этого введена специальная логическая константа UNKNOWN. В этом случае операция сравнения выглядит как: Логическое выражение > IS {TRUE | FALSE | UNKNOWN}
18. Принципы поддержки целостности в реляционных моделях данных. Языковая целостность. Ссылочная целостность. (продолжение 17 вопроса) Во-вторых, это поддержка языковой целостности, которая состоит в том, что реляционная СУБД должна обеспечивать языки описания и манипулирования данными не ниже стандарта SQL. Не должны быть доступны иные низкоуровневые средства манипулирования данными, не соответствующие стандарту. Именно поэтому доступ к информации, хранимой в базе данных, и любые изменения этой информации могут быть выполнены только с использованием операторов языка SQL. В-третьих, это поддержка ссылочной целостности (Declarative Referential Integrity, DRI), означает обеспечение одного из заданных принципов взаимосвязи между экземплярами кортежей взаимосвязанных отношений:
Ссылочная целостность обеспечивает поддержку непротиворечивого состояния БД в процессе модификации данных при выполнении операций добавления или удаления.
19. Семантическая поддержка целостности. Виды декларативных ограничений целостности Кроме указанных ограничений целостности, которые в общем виде не определяют семантику БД, вводится понятие семантической поддержки целостности, которая связана с содержанием БД. Принципы семантической поддержки целостности как раз и позволяют обеспечить автоматическое выполнение тех следующих условий:
Семантическая поддержка может быть обеспечена двумя путями: декларативным и процедурным путем. Декларативный путь связан с наличием механизмов в рамках СУБД, обеспечивающих проверку и выполнение ряда декларативно заданных правил-ограничений, называемых чаще всего "бизнес-правилами" (Business Rules) или декларативными ограничениями целостности. Выделяются следующие виды декларативных ограничений целостности: § Ограничения целостности атрибута: значение по умолчанию, задание обязательности или необязательности значений (Null), задание условий на значения атрибутов. § Ограничения целостности, задаваемые на уровне доменов, при поддержке доменной структуры. § Ограничения целостности, задаваемые на уровне отношения. Некоторые семантические правила невозможно преобразовать в выражения, которые будут применимы только к одному столбцу. § Ограничения целостности, задаваемые на уровне связи между отношениями: задание обязательности связи, принципов каскадного удаления и каскадного изменения данных, задание поддержки ограничений по мощности связи. Эти виды ограничений могут быть выражены заданием обязательности или необязательности значений внешних ключей во взаимосвязанных отношениях.
Декларативные ограничения целостности относятся к ограничениям, которые являются немедленно проверяемыми. Есть ограничения целостности, которые являются откладываемыми. Эти ограничения целостности поддерживаются механизмом транзакций и триггеров.
20. Транзакции. Триггеры и хранимые процедуры. Транзакция - это последовательность операторов манипулирования данными, выполняющаяся как единое целое (все или ничего) и переводящая базу данных из одного целостного состояния в другое целостное состояние. Транзакция обладает четырьмя важными свойствами, известными как свойства АСИД: (А) Атомарность. Транзакция выполняется как атомарная операция - либо выполняется вся транзакция целиком, либо она целиком не выполняется. (С) Согласованность. Транзакция переводит базу данных из одного согласованного (целостного) состояния в другое согласованное (целостное) состояние. Внутри транзакции согласованность базы данных может нарушаться. (И) Изоляция. Транзакции разных пользователей не должны мешать друг другу (например, как если бы они выполнялись строго по очереди). (Д) Долговечность. Если транзакция выполнена, то результаты ее работы должны сохраниться в базе данных, даже если в следующий момент произойдет сбой системы. Набор примитивов - BEGIN_TRANSACTION ; границы - END_TRANSACTION ; транзакции - ABORT_TRANSACTION; - READ; - WRITE.
Транзакция обычно начинается автоматически с момента присоединения пользователя к СУБД и продолжается до тех пор, пока не произойдет одно из следующих событий: • подана команда BEGIN TRANSACTION; • подана команда ABORT_TRANSACTION(откатить транзакцию); • произошло отсоединение пользователя от СУБД; • произошел сбой системы. Триггер- это отдельная хранимая в БД подпрограмма, связанная с таблицей или представлением, которая автоматически включается, когда в таблицу или представление вставляется (триггер добавления), модифицируется (триггер модификации) или удаляется (триггер удаления) строка. Триггеры позволяют: • Контролировать входные данные, обеспечивая достоверность информации и ее логическую непротиворечивость. • Выполнять синхронные изменения в нескольких таблицах, обеспечивая логическую целостность данных. • Обеспечить автоматическую регистрацию изменений в таблицах. Приложение может хранить полный протокол изменений, используя триггеры, которые включаются при каждом изменении таблицы. • Автоматически уведомлять об изменениях в БД, используя события, создаваемые триггерами. • Повысить независимость прикладного программного обеспечения. Изменение схемы контроля в триггере автоматически отражается во всех приложениях, не требуя внесения в них каких-либо изменений. Хранимая процедура – отдельная подпрограмма, хранящаяся и выполняющаяся на сервере СУБД. Она может получать входные параметры и возвращать значения вызвавшим её клиентским приложениям. Хранимые процедуры могут обрабатывать и возвращать отдельные записи и множество записей. SQL для триггеров и хранимых процедур содержит множество операторов императивного программирования: • конкатенацию строк, • арифметические операции, • операции сравнения, • логические (not, and, or), • операторы структурного программирования (IF, FOR, WHILE), • объявление переменных (DECLARE), • и т.д.
Эти операторы используются совместно с операторами декларативного программирования INSERT, UPDATE, DELETE и SELECT. В современных СУБД код хранимых процедур и триггеров может писаться на смеси диалектов SQL и языков высокого уровня, например, в Oracle – на PL/SQL или Java. Фактически запросы, написанные на декларативном языке, вкладываются в процедуры, написанные на императивном языке |



 В).
В). называется нетривиальной зависимостью соединения, если выполняется два условия:
называется нетривиальной зависимостью соединения, если выполняется два условия: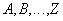 не содержит потенциального ключа отношения
не содержит потенциального ключа отношения  .
.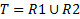
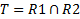
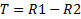
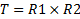
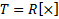 , где X – список атрибутов в схеме отношения.
, где X – список атрибутов в схеме отношения.